![]()
| Home | About | Community | Download | Documentation | Planet |
↩ Back to Developer Documentation
A quick description of the threading model
PA now supports a new RT threading model. That means that access to the audio drivers is now seperated from the main event loop. Originally, doing all stuff in the single event loop seemed to be a good idea but as we started to hook up more and more stuff (including X11 now) to the event loop this turned out to be a bad idea.
In the new model, each driver should run its I/O code in a seperate thread. Usually this means that each sink and each source are handled in a thread of their own. In some cases (like OSS) a single thread is shared for a pair for sink and source. Communication between the (non-realtime) main thread (that still exists and where a lot of code remains) and the real-time I/O threads is intended to be done entirely lock-free (at least on the RT side). For this we have added couple of lock-free APIs. Most importantly this is pa_asyncmsgq which is a message queue object where pushing and popping is most of the time a lock-free operation, unless we have to sleep an event in which case a unix pipe is used internally.
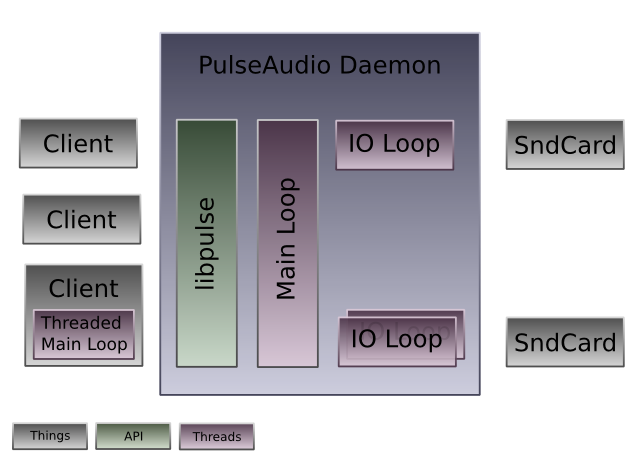
A good example for a driver that uses this new model is the OSS driver: [source:src/modules/module-oss.c module-oss.c] (this driver is quite complete but also relatively complicated due to support for both mmap and non-mmap access to the audio driver) Simpler drivers are the NULL and the pipe drivers: [source:src/modules/module-pipe-sink.c module-pipe-sink.c], [source:src/modules/module-null-sink.c module-null-sink.c] (since they do not support the full set of features they might also not be the best example, so please take this with a grain of salt)
The driver modules are responsible for starting up/shutting down the real-time threads. Where possible the PA internal thread API should be used. The module is also responsible for allocating two pa_asyncmsgq objects. One for communicating from the io thread to the main event loop, and another for the other direction. Then, every time a sink or source object is created the pa_asyncmsgq objects need to be attached to it (using pa_sink_set_asyncmsgq()). Since usually communication between the IO thread and the main thread needs to be both ways it makes a lot of sense to use the pa_thread_mq object which combines two pa_asyncmsgq objects into one: one for each direction. Even if the your driver code does not make direct use of the pa_asyncmsgq objects, you need to allocate them, because some code in PA relies on having them around.
Event handling inside the thread should be done through a pa_rtpoll object which is an event loop abstraction that supports high resolution timers. The implementing module should usually have a pa_rtpoll for each thread and should attach it to the pa_sink/pa_source objects with pa_sink_set_rtpoll().
PA now supports a very basic glib-inspired object model. See [source:src/pulsecore/object.h object.h] and [source:src/pulsecore/msgobject.h msgobject.h] for details. Every object that is a child of pa_msgobject can received messages from a pa_asyncmsgq.
Most of the methods of pa_sink/pa_source are intended to be called only from the main thread, not from the real-time threads. Notable exceptions are pa_sink_render() and friends and pa_source_post(). Many of the operations that can be done on a pa_sink object require some work in the RT threads. Due to that the default implementations will notify the RT thread via a pa_asyncmsgq. To make sure that no locking is necessary for accessing the data attached to a pa_sink the threads maintain their own copy of a couple of variables in pa_sink::thread_info.
The RT thread should look like this (in very rough pseudocode, with no error handling or anything):
void thread_func(...) {
for (;;) {
/* Write something to the device */
if (something_needs_to_be_done_for_io()) {
do_something_for_io();
continue;
}
/* TODO: update this section */
/* Give the inputs connected to this sink some extra time, if they need it */
//if (pa_sink_process_inputs(u->sink) > 0)
// continue;
/* Process the incoming pa_asyncmsgq */
//if (pa_thread_mq_process(&thread_mq) > 0)
// continue;
/* Hmm, there's no message for us, really nothing to do, than I guess we have to sleep on the device */
pa_rtpoll_run(rtpoll);
}
Of course, this is very, very rough pseudocode. Please consult one of the actual drivers for real code. The final pa_rtpoll() should be the only function where the RT thread might need to acquire a lock (which is hidden inside the kernel for us), all of the remaining code should be coded lock-free. Only if there's really nothing to do we sleep on some kernel code. Otherwise we do the best to process whatever requests we got from anywhere.
IO from/to the device is obviously our priority in the RT loop. Thus is should be the first thing to deal with in each iteration. Then, the inputs connected to our sink might need some processing time and get it through pa_sink_process_inputs(). Thirdly we process asynchronous messages from our pa_asyncmsq. Fourthly we sleep for new events. If everything is set up properly for the pa_rtpoll object our sleep ends when either messages are received on the pa_asyncmsgq, or IO events happen, or some timer expires, or any other event that is attached to the pa_rtpoll object happens. If any non-trivial processing is done in any of the parts of the RT loop you should use "continue" to restart the loop again. Of course, the question is what "non-trivial" is? I am not sure about this either, it's probably better to be here relatively liberal.
Since many of the operations that can be issued on a pa_sink are passed to the RT threads via a pa_asyncmsgq message you can overwrite your pa_sink's process_msg() function to handle them. A good example for one of the messages you probably should handle yourself is PA_SINK_MESSAGE_GET_LATENCY which you get whenever someone calls pa_sink_get_latency in the main event loop. The pa_sink object also allows you to overwrite the implementation of get_latency() entirely. You should do this instead of processing the async message, in case you can execute the operation without acquiring a lock. So basically the rule is like this: if you can do an operation (e.g. querying the latency) lock-free from the main thread, then overwrite the get_latency() function pointer. That function will be called from main event loop context. OTOH if you cannot do the operation lock-free then do not overwrite the function but instead process the PA_SINK_MESSAGE_GET_LATENCY message.
Please note that calling pa_sink_render() might take some time to compute because it involves asking every connected stream for data, resampling that and finally mixing it. Usually this operation takes more or less the same time. Unless of course the number of attached streams changes. I have no clear guideline what should be done in the driver in such a case. To avoid buffer underruns you might hook into the PA_SINK_MESSAGE_ADD_INPUT message which is sent to the pa_asyncmsgq everytime a new stream is connected to a sink and than practively enlarge the playback fragment sizes if required. This works only of course when the underlying driver supports that. If the fragment size is fixed then it might make sense to calculate the current CPU load of the RT thread and estimating for the case when the new thread is added. If it appears to be near 1 than it might be a better idea to refuse the new stream. The entirely handling of this needs to be fledged out a little bit more. Comments welcome.
Memory management in PA should be done in a zero-copy way. I.e. instead of passing around data and copying it from memory buffer to memory buffer we just pass around pointers to memory. In PA this is encapsulated by a pa_memblock, which is reference counted and should stay immutable after initialization. A ring buffer in PA terms is just a linked list of pointers to the real data (called a pa_memblockq). You can send pa_memblocks through pa_asyncmsgqs. Please do not use the oh-so-famed JACK ringbuffer for this buffer. Besides the fact that the JACK ringbuffer is borked (misuse of "volatile", missing memory barriers) it also involves copy operations which we don't want in our zero-copy PA. Please note that allocation/deconstruction of pa_memblock is lock-free and thread-safe. However, access to pa_memblockqs is NOT thread-safe. In several modules you'll find that the RT thread manages a pa_memblockq and writes pa_memblocks it receives via pa_asyncmsgq to it. That's the way it should be done.
Please note that to get to the actual data of a pa_memblock you have to call pa_memblock_acquire(). After accessing it you need to call pa_memblock_release(). This is required in some places to safely know when we can swap the actual data pointer in the pa_memblock. It is not a lock or anything, just a very simple atomic operation.
Please make sure to always have a matching pa_memblock_release() for each pa_memblock_acquire()! And also to have a matching pa_memblock_unref() for each pa_memblock_ref()!
Please note that malloc() and free() are usually not lock-free (oh, and even GSlice and stuff is not lock-free when the thread allocating the block and the one freeing it is not the same). Thus it is best to not use them from the RT thread during runtime. In many cases you can do this by calling them exclusively in the setup and construction functions. If this is not possible you should be using a pa_flist, a lock-free, thread-safe free()-list implementation. There is even a static version of this around that is used in several locations, such as the pa_hashmap implementation. To be really efficient and to guarantee lock-freeness in all cases this data structure needs to be "prefilled" with a set of memory object. Something which we don't do yet. But we'll add this in the future.
Yes, of course we could use some real guaranteed-to-be-lock-free malloc() implementation. But as of now I don't know any free enough implementation without major drawbacks. The free-list solution should be good enough for the time being.
We don't do mlock()'ing yet. Something else that we might add eventually. It is questionnable anyway if mlock()ing all memory the RT threads ever touches make sense. If there is memory pressure on the system audio is usually not the most important part that should not get paged out. Most code and data accessed in the RT thread should be "hot" anyway, so no need for mlock() protection. And for the few cases where data that might get accessed from the RT thread might indeed have been paged out it probably makes sense to call pa_memblock_will_need() or pa_memchunk_will_need() from the main event loop (which will tell the kernel to page in that specific block of memory) before passing it to the RT thread.
Yepp, this documentation is very terse and very rough. And also everything is still in flux. Hence, in case of questions: ping me on #pulseaudio, or read the source. Or better even: do both!
*Oh, this page is a wiki, so feel welcome to update it! *
Reference Counting
A few rules for reference counting:
- Increasing the refcounter should be done by a
_ref()function, decreasing with_unref() - Refcount only the pointers that point from the longer-living object to the shorter-living object - NOT the other way round!
- Provide an
_unlink()method on the short-living object that deregisters the object from the longer-living object and also unlinks every attached shorter-living object. This should not be confused with_unref() - Only use refcounting as defined in [source:src/pulsecore/refcnt.h refcnt.h] or by pa_object, because this one is guaranteed to be atomic.
Yes, not all code currently in PA abides to these rules, but this is being worked on. e.g. a couple of functions that should be called _unlink() are called _disconnect() right now.
Atomicity and Memory Barriers
Since PA now uses a (mostly) lock-free core, we provide a set of atomic integer and pointer routines in form of pa_atomic_xxx() (defined in [source:src/pulsecore/atomic.h atomic.h]). They include full implicit memory barriers, which allows you to forget about memory access ordering issues on SMP -- as long as you do use pa_atomic_xxx().
Besides that, the pa_thread_xxx thread creation/termination APIs, pa_semaphore_xxx and pa_mutex_xxx provide implicit full memory barriers. Everything that is built on top of these building blocks, such as pa_asyncmsgq thus also includes implicit memory barriers.
So, to avoid race conditions in your code, make sure to use the existing APIs and you should be able to forget about memory barriers. It is always preferable to implement algorithms lock-free. However, very often this is very difficult to get right, if possible at all. In those cases, a good solution is usually to leave the actual work on a complex data structure to the rt thread and to request it via a message on a pa_asyncmsgq (Of course only if the actual processing of this stuff is not tooo difficult, i.e. has a low complexity). Also, keeping everything lock-free is not worth it in many cases. So please, if you feel that some algorithm is best implemented with taking a lock, than just do it and don't feel bad about it. We have the pa_mutex_xxx APIs for these cases!
pa_semaphore_post() does not require taking a lock. Hence in many cases, it is better to use pa_semaphores over pa_cond.
Don't bother with implementing your own lock-free reference counting based directly on pa_atomic_xxx(). Instead, use the refcnt.h API mentioned above, or use pa_object.
Nota bene: all our memory barriers are full memory barriers. The most important architectures are x86/x86-64 where only this type of barriers exists. Since only very few people fully understand the differences between all the barriers, and we have no access to more exotic architectures the full memory barriers must suffice for our uses.